[Editor's note: this post was co-authored by Reza Nazari and Augusta Zhang]
Almost all the fellow Millennials I know have unforgettable memories of growing up playing Atari video games. As a kid, I personally spent days and nights consumed by these very low-resolution but highly addictive games. Every new level brought joy and curiosity to our lives. While I’ll never forget the kids that were far better than me—nothing is worse than childish jealousy!—today, our true competitors are not just real humans anymore. With modern advancements in artificial intelligence, we can teach computers to achieve super-human performance in many of these games.

What is reinforcement learning?
There are countless ways to define intelligence, including the ability to solve problems, to adapt to unknown situations, and to apply one’s knowledge in any given environment. At their core, all these definitions share one theme—making the right decisions at the right time, in a variety of different contexts. With artificial intelligence, computers learn to make decisions that traditionally would only be possible for humans—choices like what actions and strategies to employ to maximize a video game score.
Reinforcement Learning (RL) is the branch of AI responsible for turning computerized agents into Atari whizzes. RL algorithms generally consist of an agent that is responsible for making certain decisions within a given environment. Through the many interactions that it has in the environment, the agent learns rules for making good decisions, and continually refines them by trial and error. Using reinforcement learning, an agent can quickly master the games that we spent weeks and months practicing as children.
The CartPole-v0 problem
SAS Viya offers reinforcement learning capabilities to solve complex decision-making problems, with support for various types of algorithms. In this blog post, I’ll introduce some of the basics of SAS reinforcement learning through the classic CartPole-v0 problem, where the objective is to balance a vertical pole atop a moveable cart by moving the cart left or right. The state space of CartPole-v0 is a 4-dimensional vector, which represents the cart’s position and velocity, as well as the pole’s angle and velocity. In each time step, if the agent succeeds in keeping the pole almost vertical, the agent receives a reward of +1. If the agent can attain a cumulative reward of 200, the problem is solved.
Deep Q-Networks
There are many algorithms for solving the CartPole-v0 problem. In this blog, I’ll focus on Deep Q-Networks (DQN), which are a generalization of the classic Q-learning method.
In Q-learning, the agent tries to maximize the expected cumulative reward from any action taken during a given state of the game, which is known as the Q-value. Once the agent has access to all the Q-values, it can simply choose the optimal action at any state by selecting the one with the highest Q-value. However, as the number of states and actions grows, it becomes impossible to enumerate the Q-values for all possible state-action pairs, so researchers use approximation methods to indirectly infer the approximated Q-values, even in situations that have never been visited before.
With DQN, neural networks are used to assess each state-action pair and determine the approximated Q-values. This algorithm combines the flexibility and power of neural networks with the Q-learning method by introducing two additional pieces: a target network Q-hat and replay memory. The target network is similar to the Q-network, but it is updated less frequently, generating less volatile Q-value predictions. Likewise, the replay memory gathers many historical transactions and removes the correlation between consecutive samples.
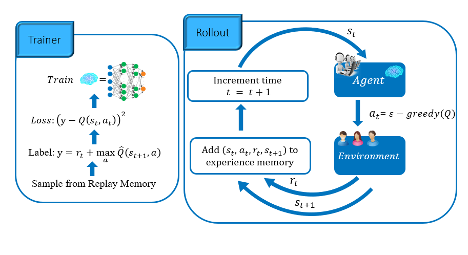
The DQN algorithm consists of two main parts and is shown in detail in the diagram below:
- Rollout: In this part of the algorithm, the agent observes the state st of the environment and uses the current Q-function to propose an action at to be applied in the next time step. To allow for exploration, it is natural to allow the agent to choose random actions at some time steps. This combination of random actions and the ones chosen from the Q-function is known as ε-greedy policy, where ε is the probability a random action is chosen. Otherwise, the action with the highest Q-value is applied. Once the action is in place, the environment dynamics will transition the environment to state st+1 and will return a reward r_t to demonstrate the quality of the chosen action. Then, the transition tuples (st,at,rt,st+1) will be stored in a replay buffer memory, and this cycle continues.
- Trainer: The trainer phase starts by randomly sampling a batch of transition tuples. After computing the target value from the target network, it computes the loss and updates the weights of the Q-network by backpropagation.
Demo
Now that we’ve reviewed the basics of the algorithm, let’s see how we can use reinforcement learning on SAS Viya to train the CartPole-v0 environment.
Try it for yourself
Reinforcement learning is available in the SAS Data Science Offerings. Try SAS Visual Data Science Decisioning for free.
Get the Jupyter notebook here.
